

Table of contents
안녕하세요, 아이엔마케팅 허휘영입니다.
2026년 6월 10일 구글이 새로운 실험용 오픈 모델 DiffusionGemma(디퓨전젬마)를 공개했습니다. 텍스트를 만드는 방식을 바꿔, GPU 환경에서 최대 4배 빠른 속도로 글을 생성하는 모델입니다.
기존의 대형 언어 모델(LLM)은 대부분 단어를 하나씩 순서대로 만들어 냅니다. 반면 DiffusionGemma는 텍스트 여러 부분을 한 번에 만들어 내는 새로운 방식을 사용해, 생성 속도를 크게 끌어올렸습니다. 이 모델은 구글의 젬마 4(Gemma 4) 모델과 제미나이 디퓨전(Gemini Diffusion) 연구를 기반으로 만들어졌으며, 누구나 활용할 수 있도록 아파치 2.0(Apache 2.0) 라이선스로 공개되었습니다. 발표된 주요 내용을 차례대로 살펴보겠습니다.
한 번에 문장 전체를 만드는 빠른 생성 방식

대부분의 언어 모델은 타자기처럼 왼쪽에서 오른쪽으로 단어를 하나씩 입력하듯 글을 만듭니다. 클라우드 서버에서는 수천 명의 요청을 한꺼번에 묶어 처리하기 때문에 이 방식이 효율적입니다. 그러나 개인 기기에서 한 사람이 사용할 때는, 단어를 하나씩 만드느라 GPU가 대부분의 시간을 다음 작업을 기다리는 데 쓰게 됩니다.
DiffusionGemma는 이 비효율을 뒤집습니다. 단어를 순서대로 예측하는 대신, 256개의 토큰으로 이뤄진 문단 하나를 통째로 한 번에 만들어 냅니다. 컴퓨터의 처리 장치에 한 번에 더 많은 일을 맡겨, 기기 성능을 최대한 활용하는 방식입니다. 글을 한 글자씩 치는 타자기에서, 한 페이지를 한 번에 찍어 내는 인쇄기로 바뀌는 것에 비유할 수 있습니다.
이러한 생성 방식은 AI 이미지 생성 원리와 비슷합니다. 흐릿한 화면에서 시작해 조금씩 선명한 그림으로 다듬어 가는 이미지 생성처럼, DiffusionGemma도 다음 세 단계를 거칩니다.
- 빈 화면 준비: 의미 없는 임시 토큰으로 채워진 빈 화면에서 시작합니다.
- 반복적인 다듬기: 여러 번에 걸쳐 정확한 토큰을 확정하고, 이를 단서로 나머지 부분을 다듬습니다.
- 최종 완성: 텍스트가 점점 정돈되어 완성된 결과물로 만들어집니다.
개발자에게 새로운 가치를 더하는 기능
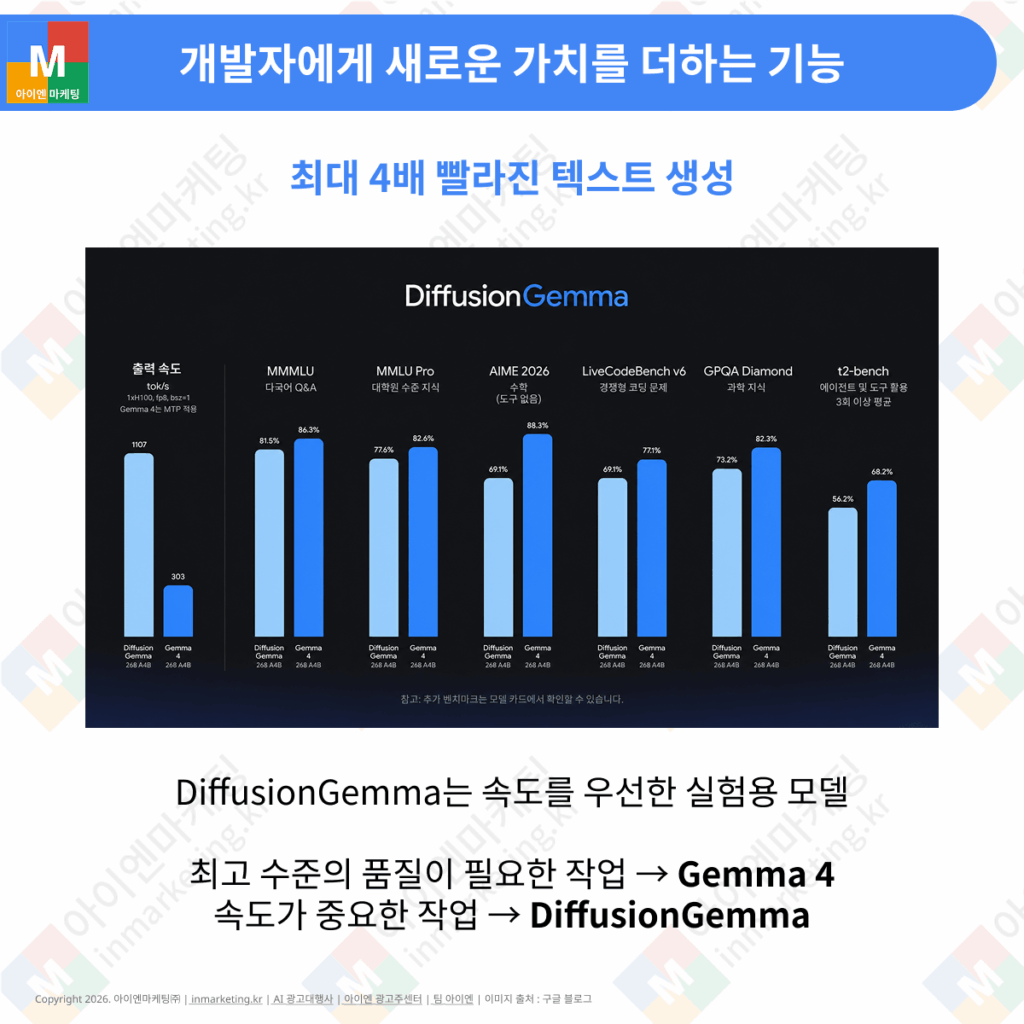
실시간으로 반응하는 AI 애플리케이션을 만드는 개발자는 개인 기기에서의 처리 지연 때문에 어려움을 겪는 경우가 많습니다. DiffusionGemma는 바로 이 문제를 풀어 주며, 주요 특징은 다음과 같습니다.
- 매우 빠른 처리 속도: 전용 GPU에서 기존보다 최대 4배 빠르게 텍스트를 생성합니다. NVIDIA H100에서는 초당 1,000개가 넘는 토큰을, GeForce RTX 5090에서는 초당 700개가 넘는 토큰을 만들어 냅니다.
- 부담 없는 하드웨어 요건: 전체 260억 개 규모의 모델이지만 실제 작동 시에는 38억 개의 변수만 사용해, 고성능 소비자용 GPU의 18GB 메모리 안에서도 무리 없이 구동됩니다.
- 양방향 처리: 256개의 토큰을 한 번에 생성하면서 각 토큰이 서로를 참고할 수 있습니다. 덕분에 문장 중간을 수정하거나 코드의 빈 부분을 채우는 작업에 강점을 보입니다.
- 스스로 고치는 기능: 모델이 자신의 결과물을 반복해서 다듬으며, 전체 텍스트를 한눈에 살펴 실시간으로 오류를 바로잡습니다.
다만 DiffusionGemma는 속도를 우선한 실험용 모델이라, 결과물의 전반적인 품질은 기존 젬마 4보다 낮습니다. 따라서 최고 수준의 품질이 필요한 작업에는 기존 젬마 4를 사용하는 것이 좋습니다. DiffusionGemma는 빠른 반복 작업이나 실시간 편집처럼 속도가 중요한 작업에 적합한 모델입니다.
다양한 환경에서 사용하는 방법

구글은 개발자가 익숙한 작업 환경에서 DiffusionGemma를 바로 사용할 수 있도록, 발표 당일부터 다양한 개발 도구를 지원합니다.
- 모델 내려받기: 아파치 2.0 라이선스로 공개된 모델을 허깅 페이스(Hugging Face)에서 바로 내려받을 수 있습니다.
- 개발 도구 활용: MLX, vLLM, 허깅 페이스 트랜스포머스 같은 도구로 모델을 효율적으로 구동할 수 있으며, llama.cpp 지원도 곧 추가됩니다.
- 하드웨어 최적화: 구글은 NVIDIA와 협력해 소비자용 GPU(RTX 5090·4090)부터 기업용 시스템까지 폭넓은 환경에 맞춰 최적화했습니다.
- 데스크톱과 클라우드에서 실행: 개인 데스크톱의 전용 GPU에서 구동하거나, Gemini Enterprise Agent Platform Model Garden과 NVIDIA NIM을 통해 클라우드에서 사용할 수 있습니다.
DiffusionGemma는 텍스트 생성 속도를 크게 높여, 실시간으로 반응하는 AI 서비스의 가능성을 넓혔습니다. 빠른 응답 속도가 중요한 챗봇이나 실시간 콘텐츠 생성 도구처럼, 속도가 곧 사용자 경험으로 이어지는 영역에서 새로운 기회가 될 수 있습니다. AI 기술을 자사 서비스나 마케팅에 어떻게 활용할지 고민하는 기업이라면, 이러한 기술 흐름을 눈여겨볼 만합니다.
아이엔마케팅은 Google과 AI의 변화에 가장 빠르게 대응하는 구글 전문 광고 대행사입니다. 내 비즈니스에 맞는 구글 광고 전략이 필요하시다면 ‘아이엔마케팅 홈페이지‘, 혹은 AI 아이엔마케팅 사이트에 방문해주세요. 자세한 상담 및 제안서를 받아보시고 싶으신가요? 지금 아이엔마케팅 홈페이지에서 무료 제안서를 신청하시고, 내 비즈니스에 최적화된 맞춤 제안서를 받아보세요.


