

Table of contents
안녕하세요, 아이엔마케팅 허휘영입니다.
2026년 4월 처음 공개된 Gemma 4가 한층 가벼워졌습니다. 2026년 6월 5일 구글이 Gemma 4의 새로운 버전을 공개했습니다. 이번 버전은 양자화 인식 학습(Quantization-Aware Training, QAT)으로 최적화되어, 모델이 차지하는 메모리를 크게 줄이고 기기에서의 성능을 한층 높였습니다. 덕분에 일상에서 쓰는 노트북이나 일반 소비자용 GPU에서도 모델을 직접 구동할 수 있게 되었습니다.
양자화는 모델이 차지하는 메모리를 줄여, AI 모델을 일 반 기기에서 구동할 수 있게 하는 핵심 기술입니다. 다만 학습이 끝난 뒤 모델을 압축하는 기존 방식은 성능이 떨어지는 경우가 많았습니다. 이번에 적용된 양자화 인식 학습은 학습 단계에서부터 압축 과정을 함께 고려하기 때문에, 모델을 압축하면서도 성능 저하를 최소화합니다.
이번 공개에서 달라진 점을 차례대로 살펴보겠습니다.
성능은 지키고 크기는 줄인 모델
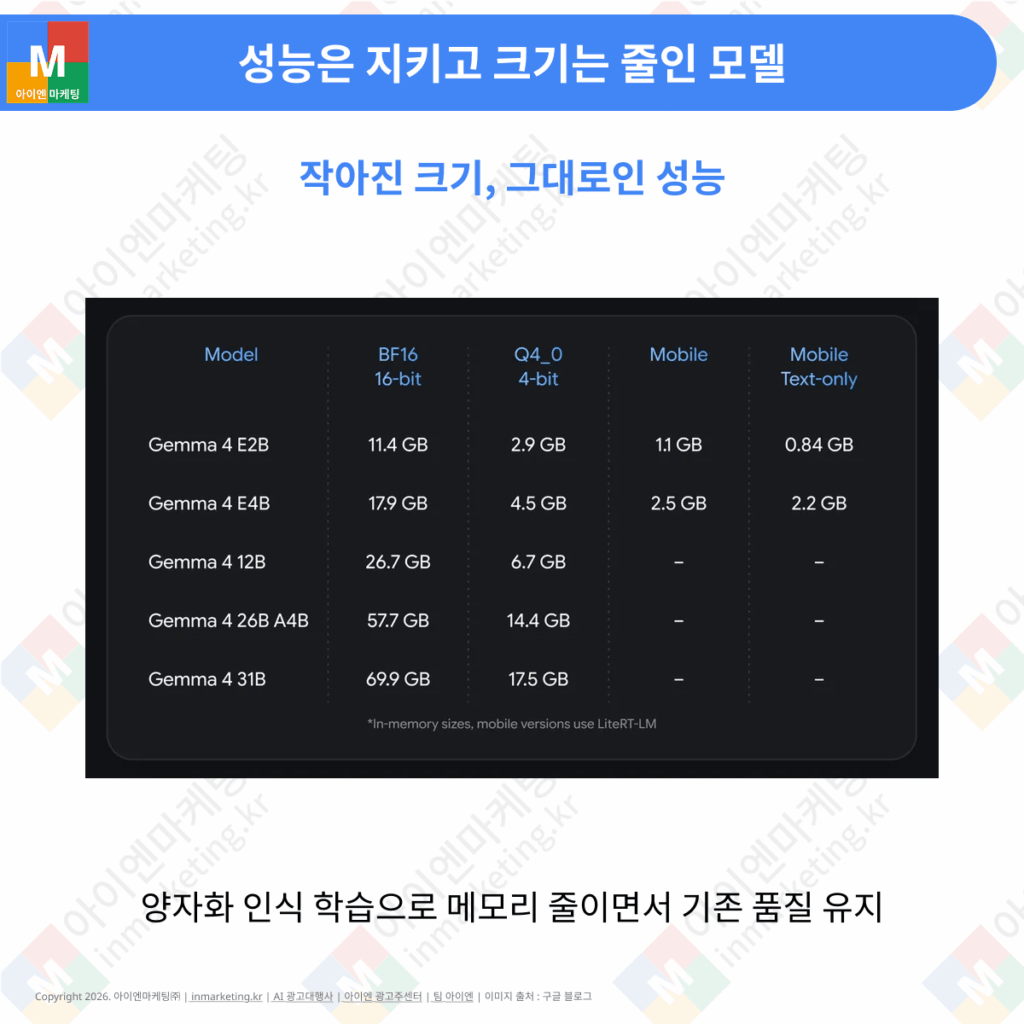
이번에 공개된 양자화 인식 학습 체크포인트는 널리 쓰이는 Q4_0 압축 형식과, 모바일 환경에 특화된 새로운 압축 형식을 함께 지원합니다. 특히 모바일용 형식을 적용해 gemma 4 E2B 모델이 차지하는 메모리를 1GB까지 줄였습니다.
기존에 널리 쓰이던 학습 후 양자화(Post-Training Quantization, PTQ) 방식은 학습이 끝난 뒤 모델을 압축하는 방법으로, 그 자체로도 성능을 잘 유지하는 편입니다. 그러나 구글의 양자화 인식 학습은 학습 과정에 압축을 함께 적용해, 기존 사후 양자화 방식보다 더 높은 성능을 보였습니다. 모델의 크기는 크게 줄이면서도 gemma 4가 제공하던 성능과 품질은 그대로 유지한 것입니다.
모바일 기기에 맞춘 최적화

일반적인 압축 형식은 모바일 프로세서에서 효율적으로 작동하기 어려운 경우가 많습니다. 구글은 gemma 4가 모바일에서도 매끄럽게 작동하도록, 소형 기기에 맞는 모바일 전용 압축 방식을 새로 설계했습니다. 주요 내용은 다음과 같습니다.
- 정적 활성화: 모델은 보통 데이터를 어떻게 처리할지 실시간으로 계산하느라 처리 능력을 소모합니다. 구글은 이 설정을 학습 단계에서 미리 계산해 두어, 모바일 칩의 부담을 줄이고 응답 속도를 높였습니다.
- 채널 단위 양자화: 압축된 데이터를 모바일 가속기의 하드웨어 구조에 맞게 정리했습니다. 덕분에 휴대폰이 느린 우회 과정 없이 계산을 곧바로 처리할 수 있습니다.
- 선택적 2비트 양자화: 토큰을 생성하는 부분은 2비트로 강하게 압축하고, 핵심 추론을 담당하는 부분은 높은 정 밀도로 유지했습니다. 이를 통해 성능을 떨어뜨리지 않으면서도 저장 공간을 절약했습니다..
- 임베딩과 KV 캐시 최적화: 모델의 어휘 목록과 단기 기억에 해당하는 부분을 집중적으로 압축했습니다. 이로써 실제 사용하는 메모리를 크게 줄여, 공간 부족 없이 긴 대화를 이어 갈 수 있습니다.
또한 음성과 영상 인식 기능이 필요 없다면, 필요한 기능만 골라 적용해 메모리 사용량을 한층 더 줄일 수 있습니다. 예를 들어 gemma 4 E2B 텍스트 전용 모델은 1GB 미만의 메모리만으로 구동할 수 있습니다.
사용 방법

구글은 개발자가 익숙한 작업 환경에서 gemma 4 QAT 체크포인트를 바로 사용할 수 있도록, 다양한 개발 도구와 협력해 발표 당일부터 지원을 시작했습니다.
- 가중치 다운로드: Q4_0와 모바일용 모델 가중치를 허깅 페이스(Hugging Face)에서 바로 내려받을 수 있습니다. llama.cpp에서 쓸 수 있는 GGUF 형식과 vLLM용 압축 텐서를 함께 제공합니다.
- 통합과 학습: 구글 공식 문서에서 QAT 체크포인트를 효과적으로 적용하는 방법을 확인할 수 있습니다.
- 데스크톱에서 사용: llama.cpp, 올라마(Ollama), LM 스튜디오(LM Studio) 같은 도구로 데스크톱에서 gemma 4 QAT 모델을 손쉽게 내려받고 관리하며 구동할 수 있습니다.
- 기기에서 바로 배포: 구글의 가벼운 LiteRT-LM 런타임으로 소형 기기에 LM Studio최적화해 배포하거나, Transformers.js로 웹에서 바로 모델을 구동할 수 있습니다.
이번 gemma 4 QAT 모델은 고성능 AI 모델을 휴대폰과 노트북 같은 일상 기기에서 직접 구동할 수 있게 해 줍니다. 모델을 클라우드 서버가 아닌 개인 기기에서 구동하면 데이터를 외부로 보내지 않고 처리할 수 있어, 비용과 개인정보 보호 측면에서 이점이 있습니다. AI 모델을 자사 서비스나 마케팅에 어떻게 활용할지 고민하는 기업이라면, 이러한 경량화 흐름을 새로운 기회로 살펴볼 만합니다.
아이엔마케팅은 Google과 AI의 변화에 가장 빠르게 대응하는 구글 전문 광고 대행사입니다. 내 비즈니스에 맞는 구글 광고 전략이 필요하시다면 ‘아이엔마케팅 홈페이지‘, 혹은 AI 아이엔마케팅 사이트에 방문해주세요. 자세한 상담 및 제안서를 받아보시고 싶으신가요? 지금 아이엔마케팅 홈페이지에서 무료 제안서를 신청하시고, 내 비즈니스에 최적화된 맞춤 제안서를 받아보세요.


